I’ve been recording introductions to each of the 15 FAIR Principles and releasing them as episodes of my Machine-Centric Science podcast (https://podcast.polyneme.xyz/).
I just released the 13th one, featuring an overview of various data and code licenses. Listen here.
Full transcript below (but also linked to via the episode landing page):
======
Hello, and welcome to Machine-Centric Science. My name is Donny Winston, and I’m here to talk about the FAIR principles in practice for scientists who want to compound to their impacts, not their errors. Today, we’re going to be talking about the 13th of the 15 FAIR principles, R1.1: metadata and data are released with a clear and accessible data usage license.
The license may be different for a data resource and the metadata that describes it. This has implications for indexing of the metadata and findability as well as ultimately using the data. It highlights the need to separate and permalink the data and the metadata.
By default, resources cannot be legally used without clarity in licensing. And furthermore, a license that cannot be found by an agent, a computational agent, is effectively the same as no license at all in a world of automated search and discovery.
There are lots of options in the world of licensing. I will go over the Creative Commons suite of data licenses, and I’ll also go over some code licenses, and relations between them.
Starting from most open, with Creative Commons, there’s CC0, no rights reserved.
After that, we have CC BY – by Attribution. This license lets others distribute, remix, adapt, and build upon your work, even commercially, as long as they credit you for the original creation. It’s the most accommodating of licenses offered that still require attribution.
Beyond that, there’s the CC BY SA – attribution and share-alike. This license let’s others use your work, even for commercial purposes, as long as they credit you. And also they need to license their new creations under identical terms. So all new works based on the work will carry the same license. The attribution share-alike is the license used by Wikipedia.
Closing up things a bit, we have attribution-no-derivatives, CC BY ND. This license lets others reuse the work for any purpose, including commercially. However, it cannot shared with others in adapted form, so you can’t make any changes.
Closing things up a bit more there’s attribution, but noncommercial, so you can use the stuff, but non-commercially. You can provide derivative works, but the derivative work that’s distributed has to be non-commercial.
Further down the line there’s attribution non-commercial share-alike. This lets others remix, adapt, and build upon your work non-commercially, as long as they credit you and license their new creations under identical terms.
And finally, attribution, non-commercial, no-derivatives just allows people to download the work, share them with others as long as they credit you, but they can’t change the work in any way or use it commercially.
So, those are the Creative Commons licenses typically use for data. Then there are the code licenses, and these aren’t quite along the same spectrum of open to closed. Rather, the spectrum is more going from maximizing user freedom to maximizing redistributor freedom.
The most user-free license that I’ve encountered recently that’s in popular use is the Server Side Public License that’s in use by, say, MongoDB. And this is akin to the Creative Commons attribution share-alike license, but additional sharing. So if someone’s offering this software as a managed service, they have to supply the source code and they also have to supply the source code for all of the service tooling that’s helping them to provide that service, like managed backups, et cetera. So, it goes even beyond the actual code. So it really makes sure that whoever is using the software really can reproduce the use. And so that maximizes that.
A little bit less than that, keeping to the domain of the actual code itself is the Affero GPL, the AGPL. That’s more akin to CC attribution share-alike, where even if you’re distributing the code through a service online, through a managed service, and you’re not actually distributing the source code directly, you still have to supply the source code to the users.
Okay, going down, there’s then the GPL, the GNU Public License. Here, if you’re offering the software as a service, you don’t have to include source modifications – it’s only if you’re actually distributing the source code.
Then, we have some licenses that are more compartmentalized to the actual portions of the code that’s being reused. So there’s the Lesser GPL and the Mozilla Public License, which are, again, like Creative Commons with attribution and share-alike, but if those licensed components are combined with other software, the user does not have the right to have the source code for all the other components that are necessary to use the system. They only have the right to modifications made to your component that is under the Mozilla Public License or Lesser GPL. But there may be other parts of the software system, as distributed, that are protected, are proprietary.
So this kind of gives a bit more freedom to the redistributor if they have proprietary code that they want to mix in, or pair with, rather, the open software. So it kind of makes the user have a little bit less insight into the total software of the system, but they still have insight into your component that you’ve released under LGPL or Mozilla Public License, MPL.
There is the Business Source License. This is kind of akin to a Creative Commons by attribution, noncommercial license that typically reverts to a by-attribution, commercial-okay license. So, Business Source License, like Sentry’s monitoring service, has an Additional Use Grant, which says, you can use this however you want as long as you do not offer commercially a managed service. So only we, the company that makes this software, can offer a managed service where we offer this to third parties. But as a user, you can do whatever you want internally. You just can’t also be a company that sells this software as a service to other companies.
So again, this offers a lot of user freedom, but has a bit more emphasis on redistributor freedom to clamp down on use. And Elasticsearch’s Elastic License is similar in the sense that a user can sort of do whatever they want with it, but they’re restricted from redistributing it commercially as a service.
Then, going down more towards freedom of the redistributor, we have things like the Apache 2.0 license, which is more like a Creative Commons with attribution, and also adds in some share-alike for contributions. So by default, anyone contributing to an Apache 2 codebase also grants their contributions to be distributed under the same license.
And then, the most so-called permissive licenses are things like the BSD license, Berkeley Software Distribution, and the MIT license, and those are more akin to just Creative Commons attribution. So there’s really no other restrictions or conditions on use, about things that are analogous to share-alike or non-commercial or non-derivative or you can’t offer this as a managed service, or if you do, you need to offer all of the code for your associated tooling for the service. It kind of places the most freedom on someone who has the software and is wanting to redistribute it or repurpose it in some way. So those are generally going to be the most compatible options with everything else.
One other license I wanted to bring up a bit just in the context of this podcast and science – there’s a fun license called the CRAPL. And it’s a quote unquote academic-strength open-source license. I wouldn’t necessarily recommend it, but I want to bring it in here just so that I can compare it to some of the other licenses that I’ve mentioned.
In the software world, I would say that the CRAPL is similar to a Business Source License with no Change License – a business source license, normally after a certain period, like two or three years, will turn into a much more permissive license, so it will become actually Open in the sense of the Open Source Initiative. And the CRAPL has the Additional Use Grant, in the context of a Business Source License, that it is only for validating published claims and validating pre-publication claims. And furthermore, the use grant allows one to publish those claims on the conditions that (1) the original author is notified of the use and claims prior to submission, and (2) that those modifications are released under the CRAPL when the supporting claims are publicly released, say, in a publication.
So, this is also kind of like the Creative Commons by attribution, non-commercial, share-alike, with the additional condition that a good faith attempt is made to notify the original author prior to public claims and distribution of your modifications.
So in summary, there are a bunch of widely used licenses. Popular licenses in the data world are the Creative Commons suite. Popular licenses in the code world are things like Apache 2.0, BSD, MIT, Mozilla Public License, the GPL – Lesser, Affero – and also newer ones that extend the others to noncommercial restrictions, like the Business Source License and the Server Side Public License, or, rather, conditions on commercial use.
If your data and metadata are not covered clearly and accessibly by one of these licenses, or if there are additional restrictions, if those aren’t clearly and accessibly provided, then reuse of your data is going to be jeopardized.
That’ll be it for today. I’m Donny Winston and I hope you join me again next time for Machine-Centric Science.
Subscribe to get short notes
like this on Machine-Centric Science delivered to your email.
]]>

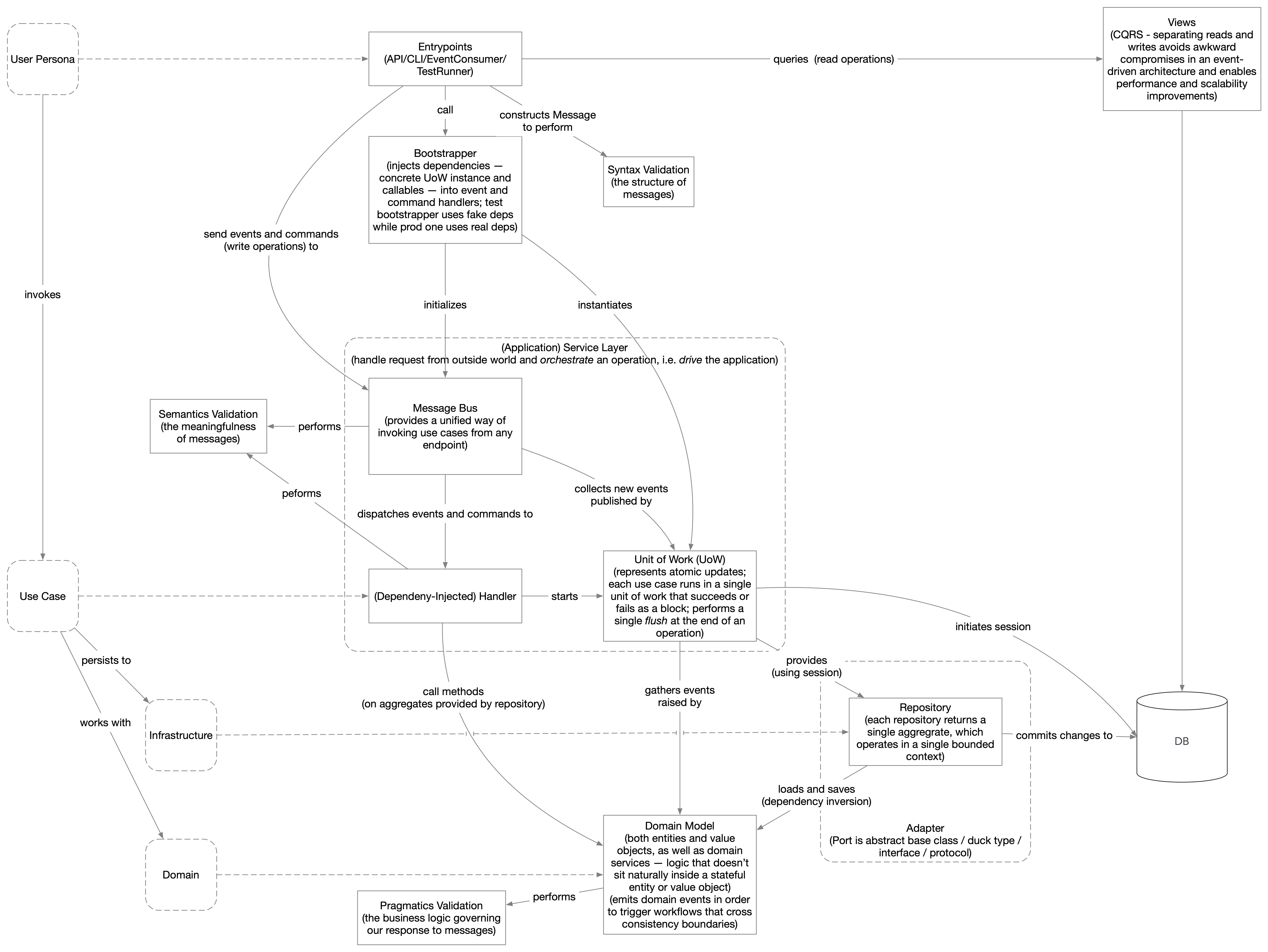
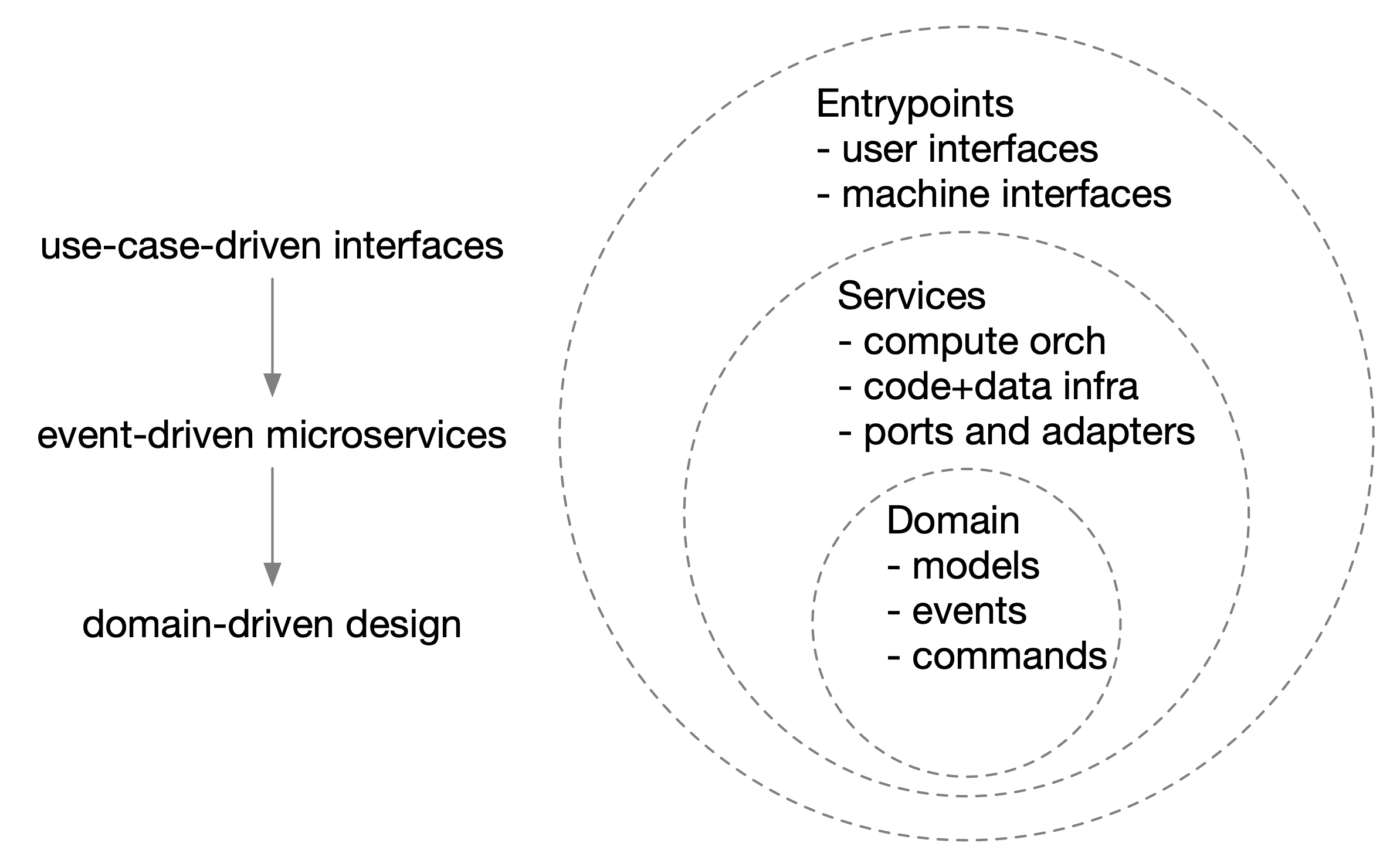
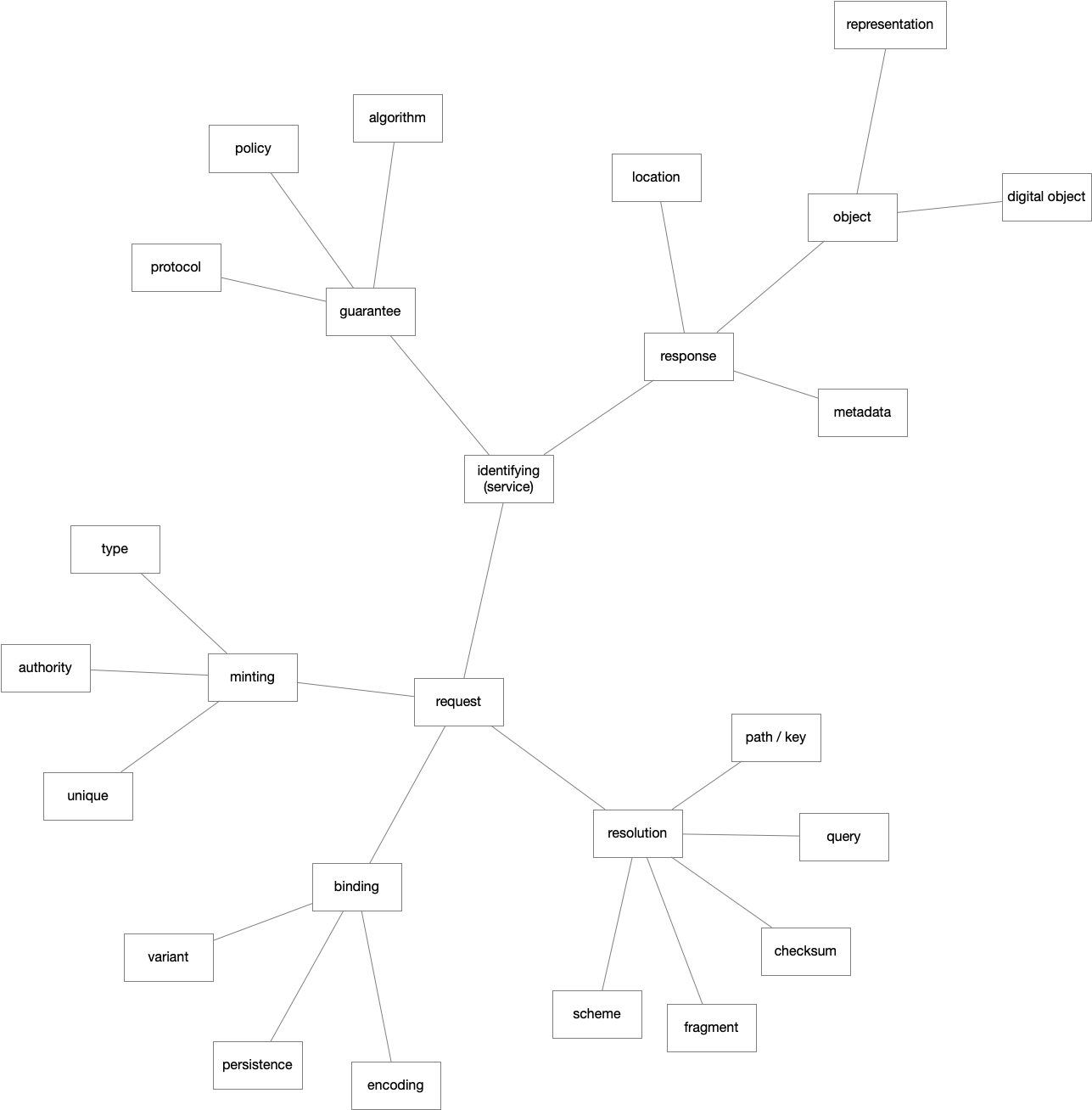



 illustration of the hourglass Internet architecture showing the six layers, from top to bottom: specific applications, application protocols, transport protocols, network protocols, data-link protocols, and physical-layer protocols. A FAIR Digital Object (FDO) protocol could extend the HTTP application protocol.")
 framework - the identifier record, identifier resolution behavior, typing, and metadata schemas and records.")















{kind=link}