From Platforms to Microservices for FAIR Data and Analysis
The “one platform1 to rule them all” is unlikely to be realized for scientific research in any domain. Rather, instead of small and numerous on-premises silos for data + code + compute, we are on track to achieve large and somewhat less numerous cloud-based silos.2
What’s the alternative? A focus on microservices – so-called to emphasize that they generally do not stand alone, but rather are components of larger workflows/services – such as data-slicing and data-summary-layer services that allow you to bring big data to code+compute by effectively subsetting/streaming it.2
But how? One approach is to pursue domain-driven design that is devoid of architecture/orchestration concerns but that yields domain events, wrapped by event-driven microservices that deal with specific technology choices, wrapped finally by entrypoint interfaces driven by user/user-agent personas and their use cases.3
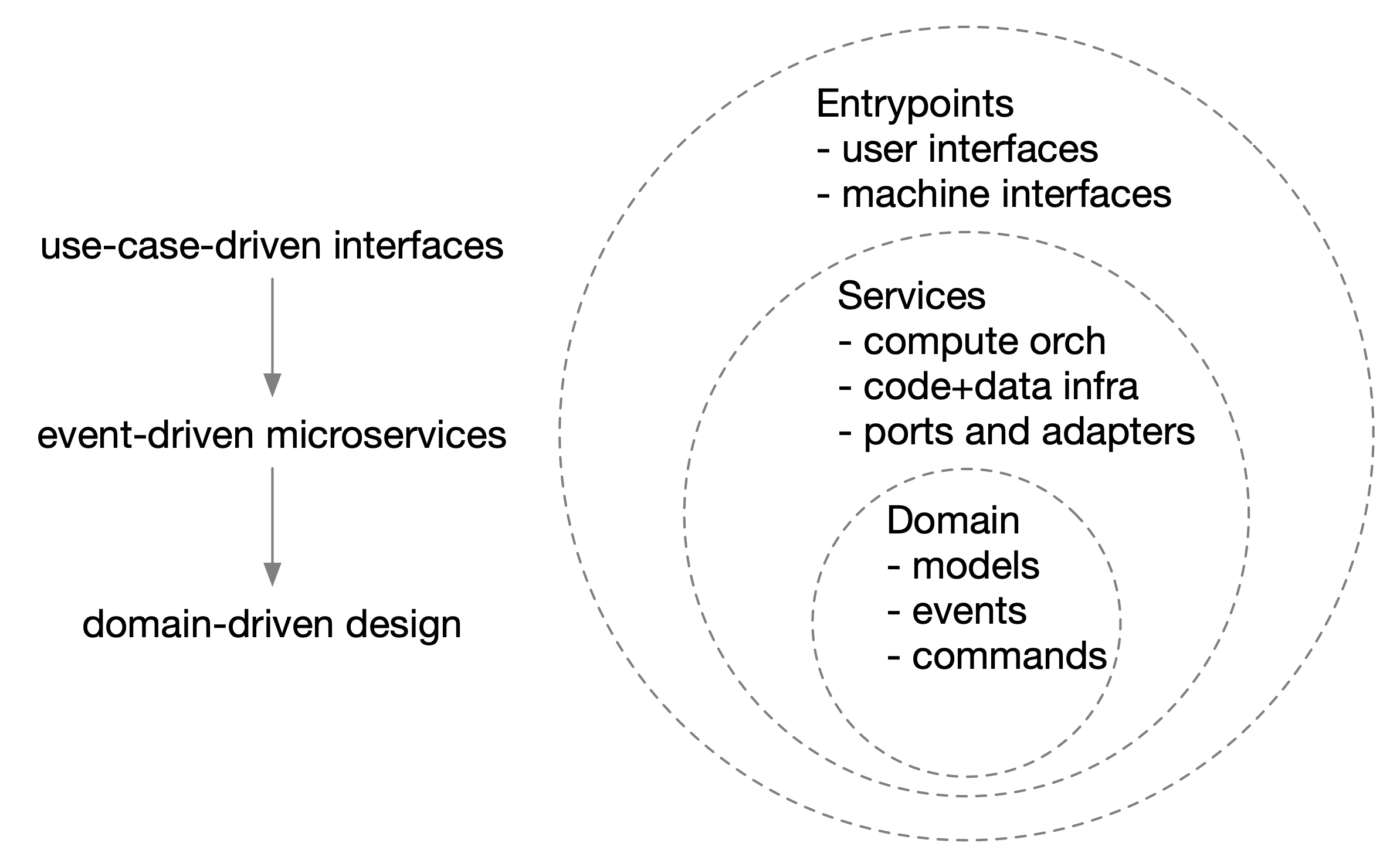
Entrypoints wrap services (orchestration, infrastructure, glue code) that wrap domain conceptualizations.
References
aka gateway, aka portal, aka virtual research environment, aka… ↩︎
N. C. Sheffield et al., “From biomedical cloud platforms to microservices: next steps in FAIR data and analysis,” Sci Data, vol. 9, no. 1, Art. no. 1, Sep. 2022, doi:10.1038/s41597-022-01619-5. ↩︎ ↩︎
H. J. W. Percival and R. G. Gregory, Architecture patterns with Python: enabling test-driven development, domain-driven design, and event-driven microservices, First edition. O’Reilly, 2020. (available online). ↩︎