Opening the World to Infer; Closing It to Validate
Scientific data is distributed over time. For a given entity of interest, have we already recorded all potentially relevant data on its properties, relationships, and representations? Have we already enumerated all of an entity’s potential attributes for which to slot in such data? Have we already named all possible types of entities of interest in our domain?
An “open-world assumption” can ease data interoperability over time in a domain, as applications come and go.
In a closed-world data model, if an entity is not in the database now, it doesn’t exist (perhaps it will in a “later” world, but not this one). A closed-world model facilitates validation, which is important in applications.
In an open-world model, if an entity is not in the database now, it may exist – we can’t claim it doesn’t. However, an open-world model shines at deductive inference of true yet not-explicitly-entered facts, which is helpful in knowledge domains (and downstream applications).
I drafted a diagram below to try and illustrate the benefit of open-world modeling for domain data.
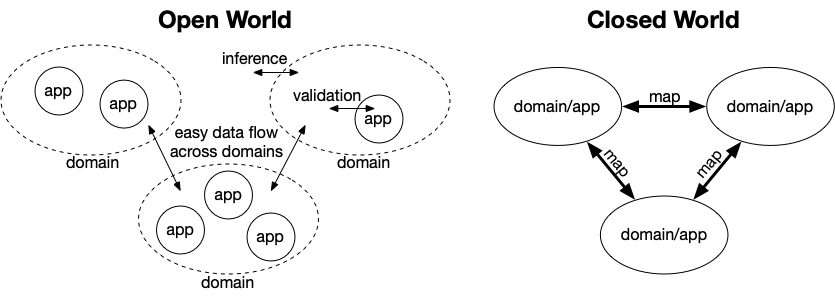
With open-world domains, interdisciplinary data flow doesn’t require explicit domain-domain data mappings. Rather, each domain can set up its own inference rules to deduce mappings for datasets. Once in the language of a domain, each application in that domain can “close the world” with a validation funnel for data relevant to the application.
On the other hand, when domain models are tightly coupled to identified applications, the world closes early, and explicit mappings are needed to share structure-bound data.
I offer one additional diagram below to illustrate a difference in processing for closed-world and open-world domain data. For closed-world data X, one maps that data to domain/application Y; it may “grow” or “shrink”, but it’s a transformation. For open-world data, on the other hand, there is first an inference step, where the set of facts grows. Then, for any given application, the data shrinks on validation for the world of the application.

This turned out to be a long note. Bad Donny. But I hope I got across a sense of a means to decouple domain data/knowledge management from application data management, and of how this decoupling could be valuable in particular for the (conceptual + temporal) open-endedness of interdisciplinary scientific research.