Reuse of Conceptual Models
As part of her introduction to ontology enginering,1 Prof. Maria Keet has a slide depicting ontology as a layer apart from conceptual data models:
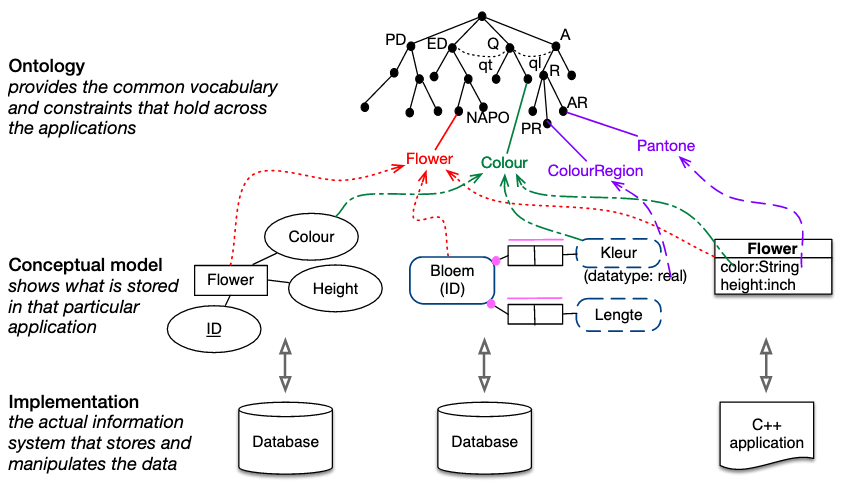 Conceptual data models vs. ontologies.
[source]
Conceptual data models vs. ontologies.
[source]I like this visualization of various project-specific conceptual models and their associated implementations in databases and codebases. This highlights the problem of disconnected conceptual models that require recurring human-human communication to reconcile and facilitate data/model reuse.
Ontologies are a technique to better facilitate such reuse. They make (dis-)agreement among people more explicit than is possible through informal conceptual models, thereby better representing the knowledge of a subject domain. Practically, they improve computer-computer, computer-human, and human-human communication.
An ontology uses logic, through terminology and assertions, to structure and constrain meaning. A quality ontology can represent all that you want to represent – your intended models – and not much more.2 It is a formal commitment to a conceptualization that is amenable to automation, especially automated reasoning.
Contrast the ontology-layer approach to conceptual-model integration with an implementation-layer approach. An example
of this latter approach with which I’m familiar is that of the Materials Project (MP),
which uses
key Python codebases to facilitate reuse of project-specific conceptual models. Over several years, any research
effort under the purview of MP has needed to include among its outputs at least one artifact in the
pymatgen codebase – e.g., a new class/module – in addition to more traditional artifacts
like publications. This addition to pymatgen (hopefully) connects to previous and future conceptual models via
reuse of existing models-in-code such as pymatgen’s Structure and PhaseDiagram classes.
Implementation-layer connection of conceptual models can work as long as all relevant stakeholders use the codebase and contribute/update implementations. This same strategy is used again within MP for reuse of computational workflows with the atomate codebase (which builds atop pymatgen). But this only works at the application layer. A materials scientist working in a language other than Python, or even in another Python codebase such as AiiDA – an alternative to atomate for computational science workflows – cannot directly reason about an atomate workflow’s conceptual model. The only place that model is formalized is in lines of atomate code, in an implementation that may need to be run (with dependencies properly installed) to be understood.
Ontologies help to organize and integrate knowledge. They deal with classes and their relationships and constraints in ways compatible with, but also more powerful than, classical object-oriented programming. They are building blocks for reuse, without being hard-coded.
References
Keet, An Introduction to Ontology Engineering, 2020. ↩︎
Just as implementations can be incrementally extended to widen what is representable, so too can ontologies be extended. ↩︎